Harvesting in Ceres
Harvesting Architecture
Section titled “Harvesting Architecture”Ceres harvests dataset metadata from open data portals and indexes them with vector embeddings for semantic search. Since portals can host tens of thousands of datasets, and embedding generation requires paid API calls, Ceres implements a two-tier optimization strategy to minimize both portal API calls and embedding API costs.
Two-Tier Optimization
Section titled “Two-Tier Optimization”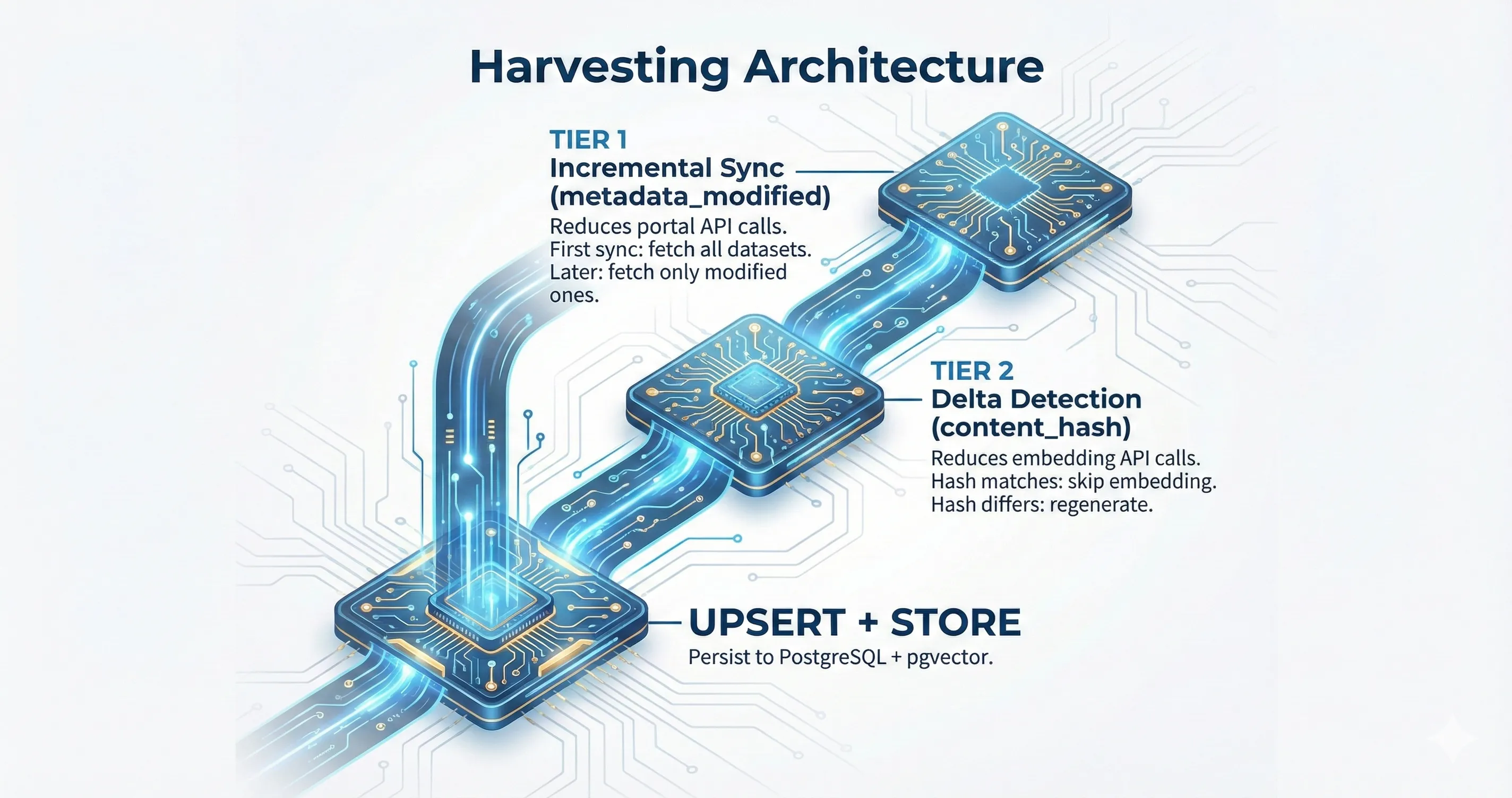
Incremental sync reduces portal calls, delta detection reduces embedding calls.
Streaming Pipeline
Section titled “Streaming Pipeline”Since v0.3.0, the harvest pipeline streams datasets through the processing stages instead of loading all datasets into memory at once. This allows Ceres to handle very large portals (100k+ datasets) with a constant memory footprint. Batched embedding API calls further improve throughput by sending multiple texts per request.
Tier 1: Incremental Sync
Section titled “Tier 1: Incremental Sync”Incremental sync uses CKAN’s package_search API with a metadata_modified filter to fetch only datasets that have changed since the last successful sync. The last sync timestamp is stored in the portal_sync_status table.
On the first sync for a portal, or when --full-sync is passed, Ceres performs a full sync by listing all dataset IDs and fetching each one. If an incremental sync attempt fails (e.g., the portal doesn’t support the metadata_modified filter), Ceres automatically falls back to a full sync.
What it saves: portal API calls. Instead of fetching metadata for all 50,000 datasets on every run, only the handful that changed since the last sync are fetched.
Tier 2: Delta Detection
Section titled “Tier 2: Delta Detection”Even when a dataset is fetched (because its metadata_modified timestamp changed), its embeddable content (title + description) may not have actually changed. For example, adding a tag or updating a resource URL changes metadata_modified but doesn’t affect what Ceres embeds.
Delta detection computes a SHA-256 hash of title + description (the content_hash) and compares it against the stored hash. If the hash matches, the embedding regeneration is skipped entirely.
What it saves: embedding API calls. In typical runs, 99%+ of datasets have unchanged content, saving significant API costs.
Why Both Tiers Are Necessary
Section titled “Why Both Tiers Are Necessary”| Scenario | metadata_modified changed? | content_hash changed? | Action |
|---|---|---|---|
| Tag added to dataset | Yes | No | Fetch metadata, skip embedding |
| Resource URL updated | Yes | No | Fetch metadata, skip embedding |
| Title rewritten | Yes | Yes | Fetch metadata, regenerate embedding |
| New dataset published | N/A (new) | N/A (new) | Fetch metadata, generate embedding |
| Nothing changed | No | N/A (not fetched) | Not fetched at all |
Without incremental sync, every run would fetch all datasets from the portal. Without delta detection, every fetched dataset would trigger an embedding API call. Together, they minimize both sources of cost.
Sync Outcomes
Section titled “Sync Outcomes”Each dataset processed during a sync receives one of these outcomes:
| Outcome | Meaning | Embedding generated? |
|---|---|---|
Created | New dataset, not seen before | Yes |
Updated | Content hash changed (title or description modified) | Yes |
Unchanged | Content hash matches stored value | No |
Failed | Error during processing | No |
Skipped | Circuit breaker is open, dataset skipped | No |
These are tracked via SyncStats and reported at the end of each sync operation.
CLI Flags
Section titled “CLI Flags”| Flag | Tier 1 (Incremental) | Tier 2 (Delta Detection) | Use case |
|---|---|---|---|
| (none) | Incremental if previous sync exists | Always active | Normal operation |
--full-sync | Full sync forced | Still active | Re-scan portal after known issues |
--dry-run | Dry run (no writes) | Still active | Preview what would happen |
Delta detection is always active regardless of flags. There is no flag to bypass it — if you need to force full re-embedding, delete the stored content hashes from the database.
Database Tracking
Section titled “Database Tracking”The portal_sync_status table tracks sync history per portal:
| Column | Type | Purpose |
|---|---|---|
portal_url | VARCHAR (PK) | Portal identifier |
last_successful_sync | TIMESTAMPTZ | Timestamp used for next incremental sync |
last_sync_mode | VARCHAR(20) | "full" or "incremental" |
sync_status | VARCHAR(20) | "completed" or "cancelled" |
datasets_synced | INTEGER | Number of datasets processed |
updated_at | TIMESTAMPTZ | When this record was last updated |
The last_successful_sync value is set to the sync start time (not end time), ensuring no datasets are missed between syncs.
Content hashes are stored in the datasets table in the content_hash column (VARCHAR(64), nullable for backward compatibility with records indexed before delta detection was added).
Circuit Breaker
Section titled “Circuit Breaker”The embedding API (Gemini) is protected by a circuit breaker to prevent cascading failures during harvesting:
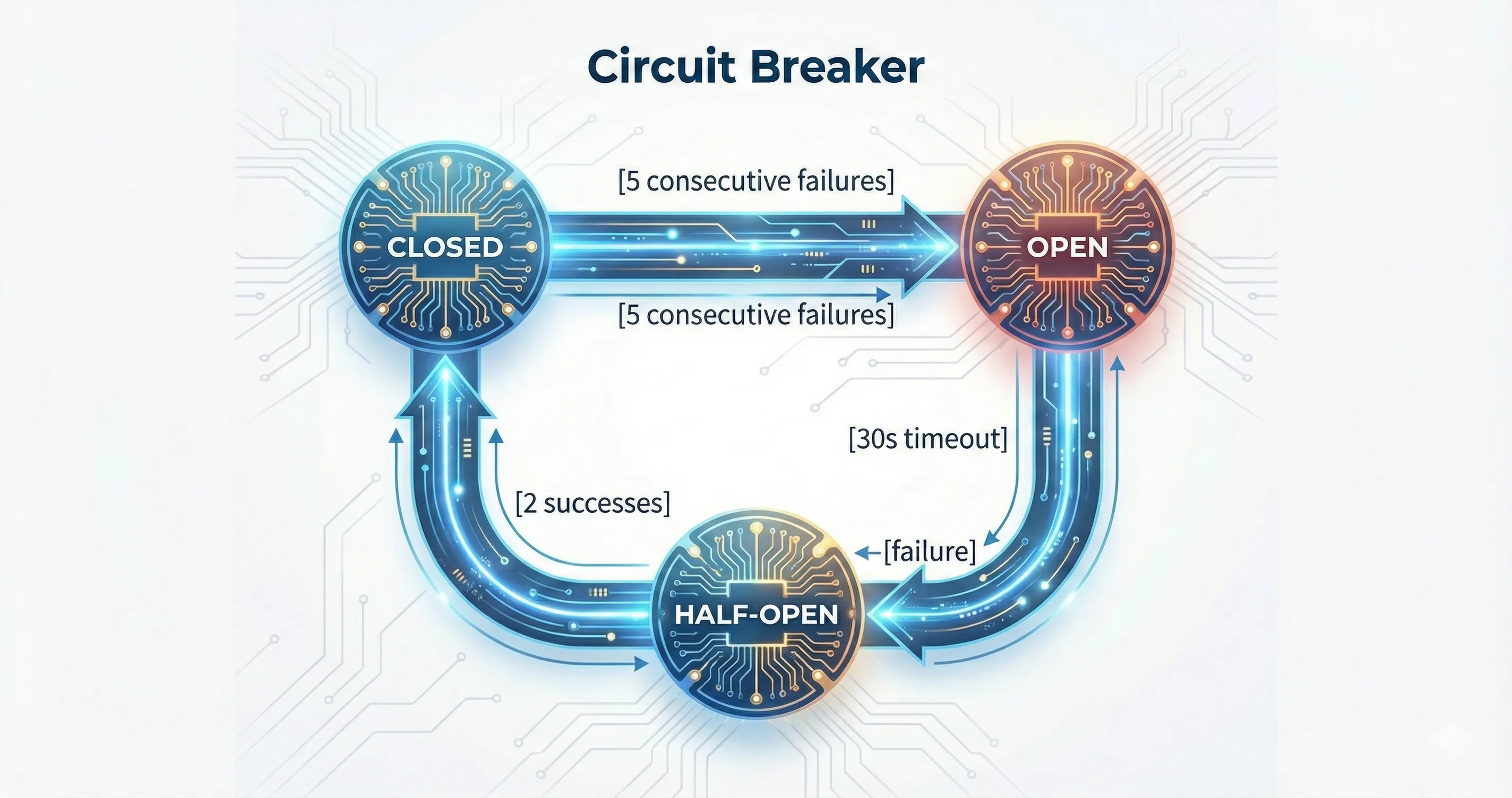
Closed, Open, Half-Open states with adaptive recovery timeout on rate limits.
- Closed: requests flow normally
- Open: all embedding requests are rejected immediately, datasets are recorded as
Skipped - Half-Open: requests are allowed to probe recovery; 2 successes close the circuit, any failure reopens it
On HTTP 429 (rate limit), the recovery timeout is multiplied by a backoff factor (default 2x), up to a maximum of 5 minutes. Configuration is via environment variables: CB_FAILURE_THRESHOLD, CB_RECOVERY_TIMEOUT_SECS, CB_SUCCESS_THRESHOLD, CB_RATE_LIMIT_BACKOFF_MULTIPLIER, CB_MAX_RECOVERY_TIMEOUT_SECS.
Related Source Files
Section titled “Related Source Files”- Harvesting service:
crates/ceres-core/src/harvest.rs - Delta detection logic:
crates/ceres-core/src/sync.rs(needs_reprocessingfunction) - Content hash computation:
crates/ceres-core/src/models.rs(NewDataset::compute_content_hash) - Circuit breaker:
crates/ceres-core/src/circuit_breaker.rs - CKAN client:
crates/ceres-client/src/ckan.rs(search_modified_since) - DB schema:
migrations/