Harvesting Is The Hard Part
Open data work usually breaks on synchronization, portal quirks, and stale records before search even starts.
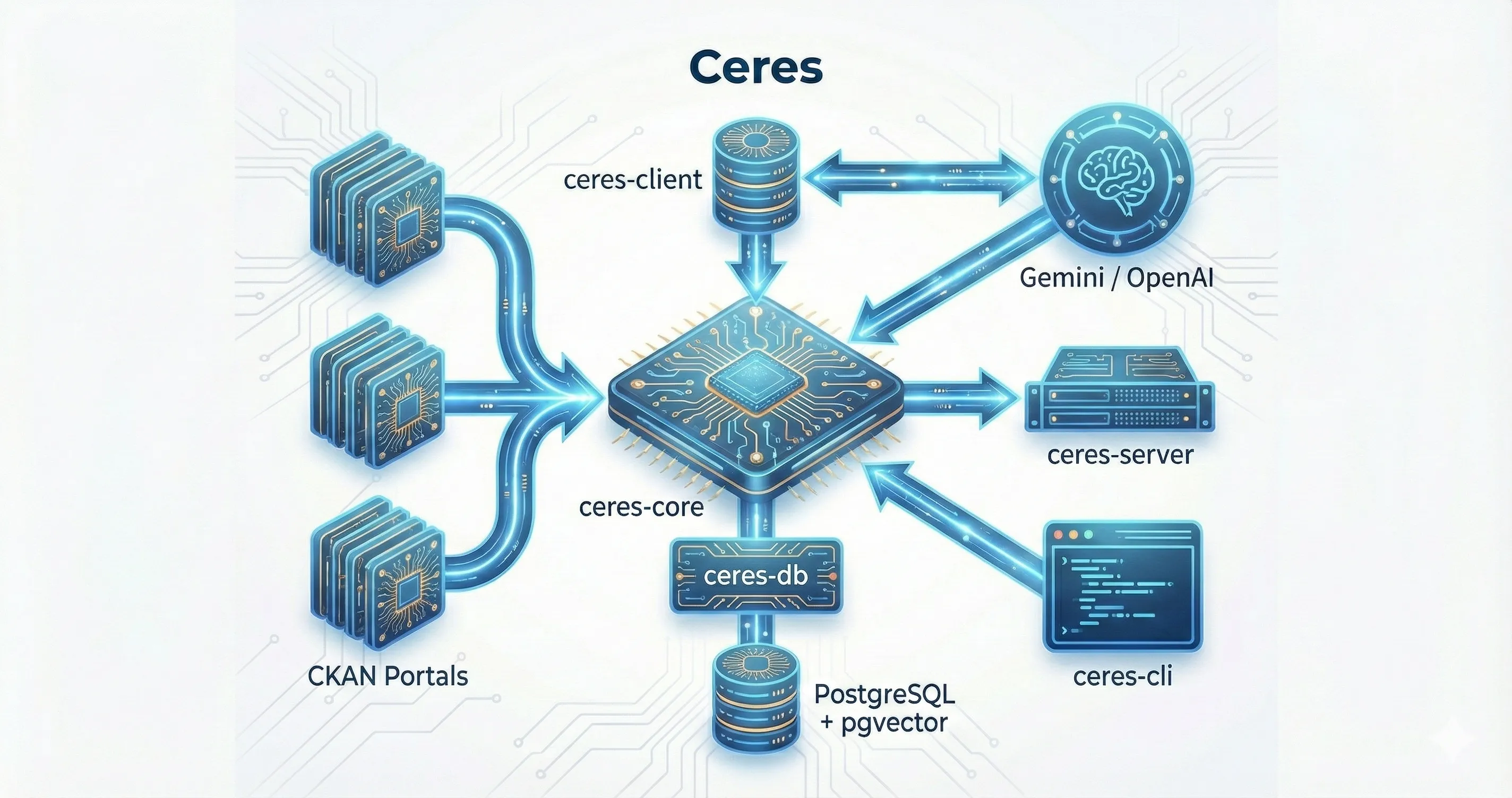
Ceres harvests metadata from open data portals and keeps a local catalog in sync over time. Embeddings, semantic search, and exports sit on top as optional layers.
Named after the Roman goddess of harvest and agriculture.
Harvesting Is The Hard Part
Open data work usually breaks on synchronization, portal quirks, and stale records before search even starts.
Portals Are Fragmented
CKAN and DCAT portals expose different capabilities, languages, and reliability profiles.
Embedding Should Be Optional
Many teams need a trustworthy harvested catalog first, then decide later whether to add local or hosted embeddings.
Ceres is designed around that order of work: harvest first, embed later if useful, search once the catalog is ready.
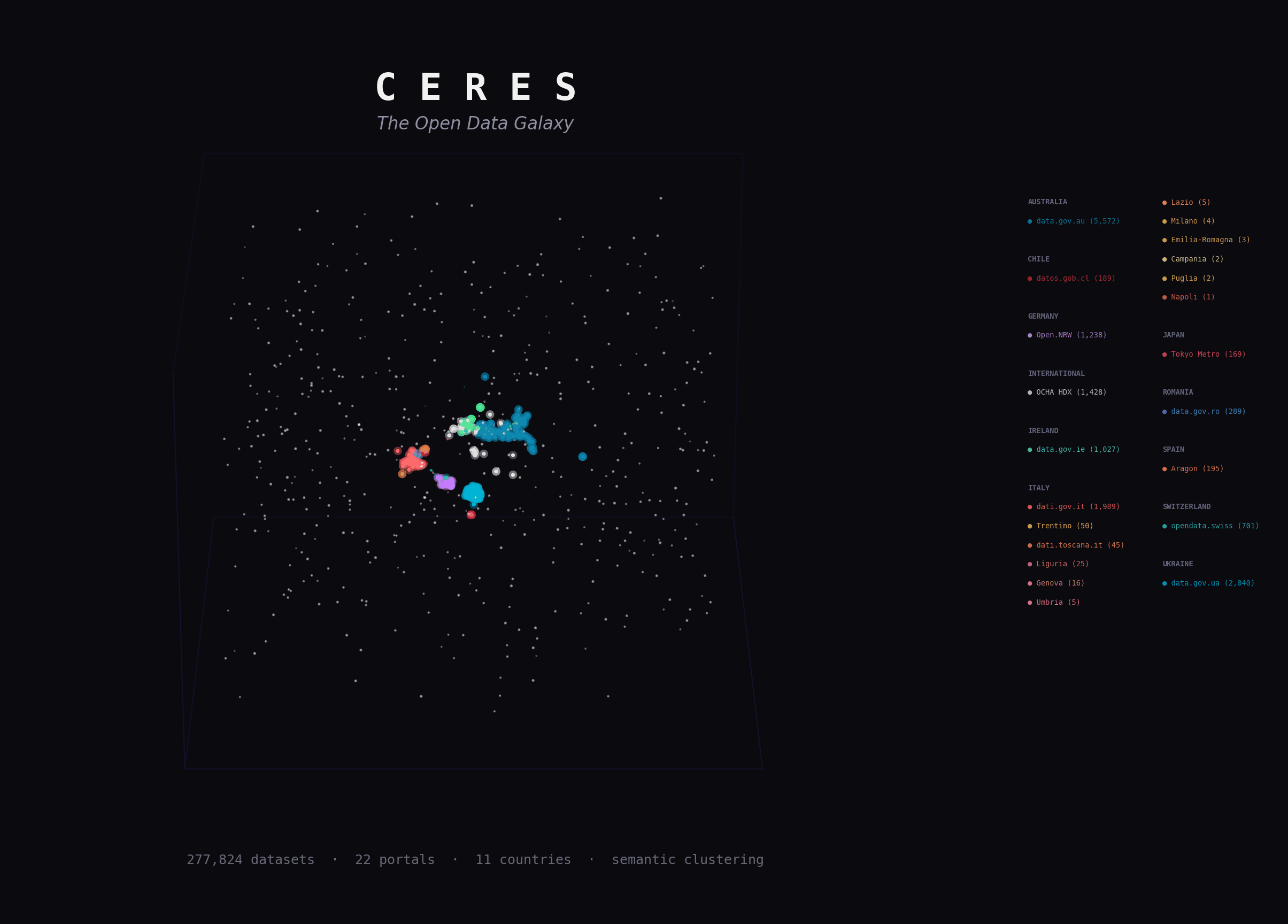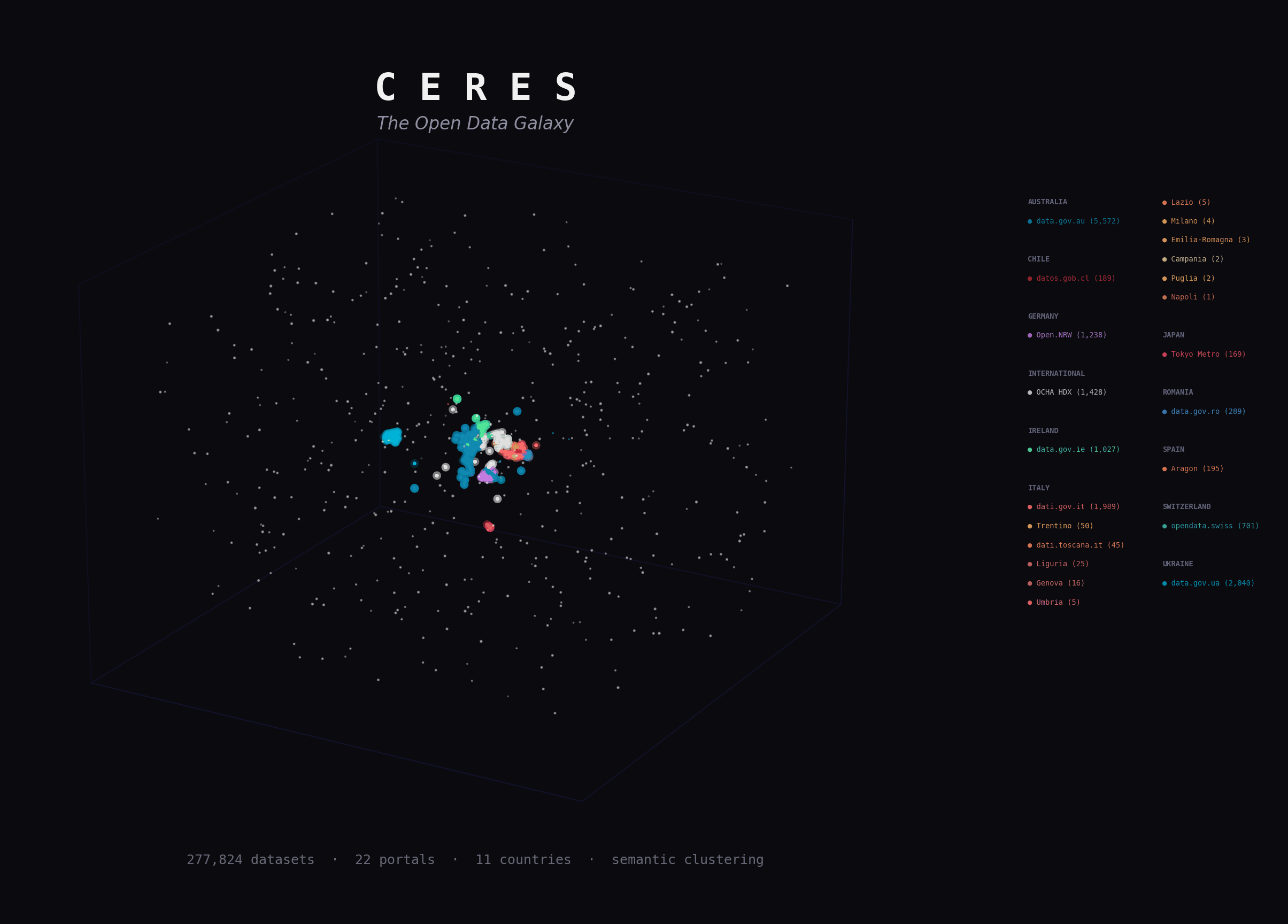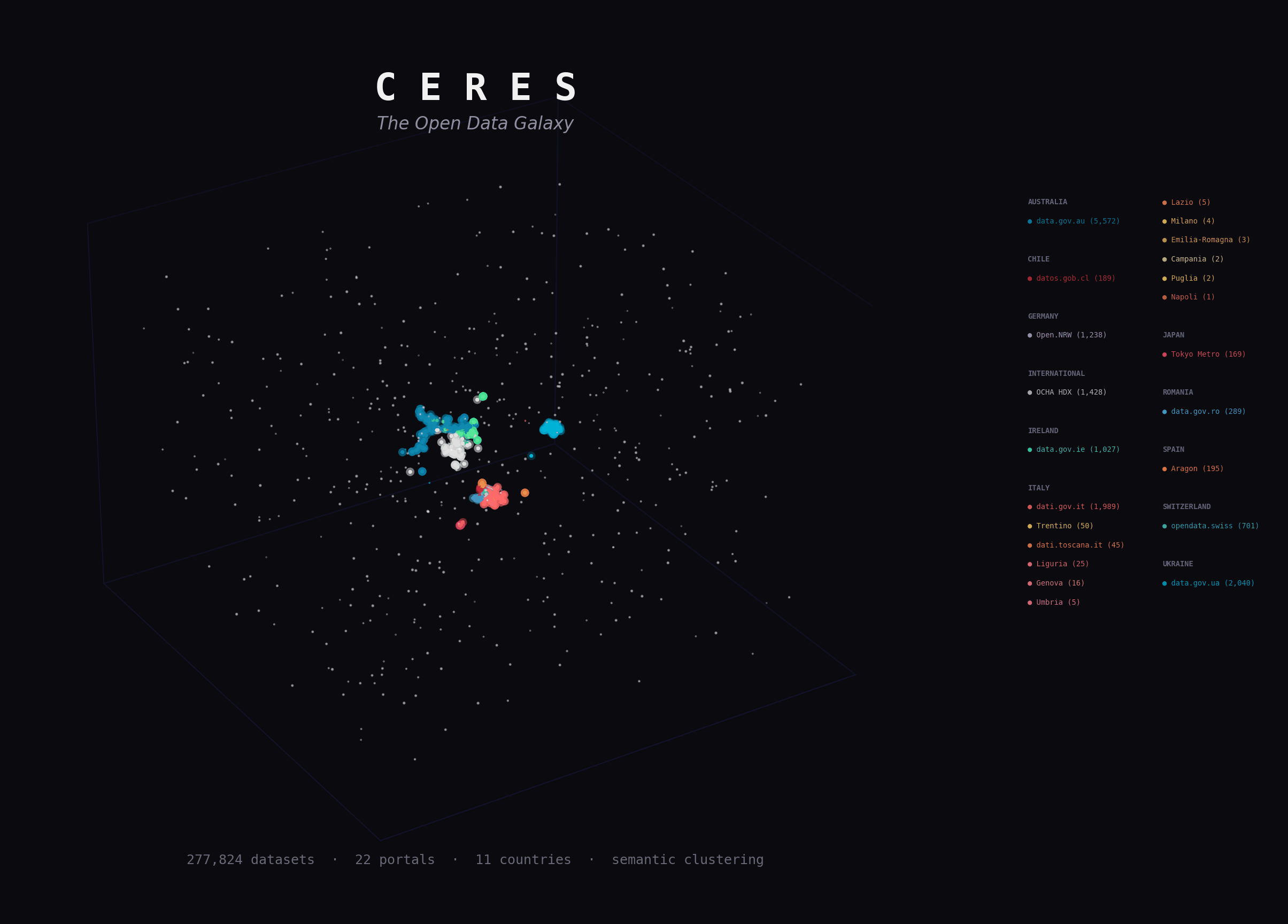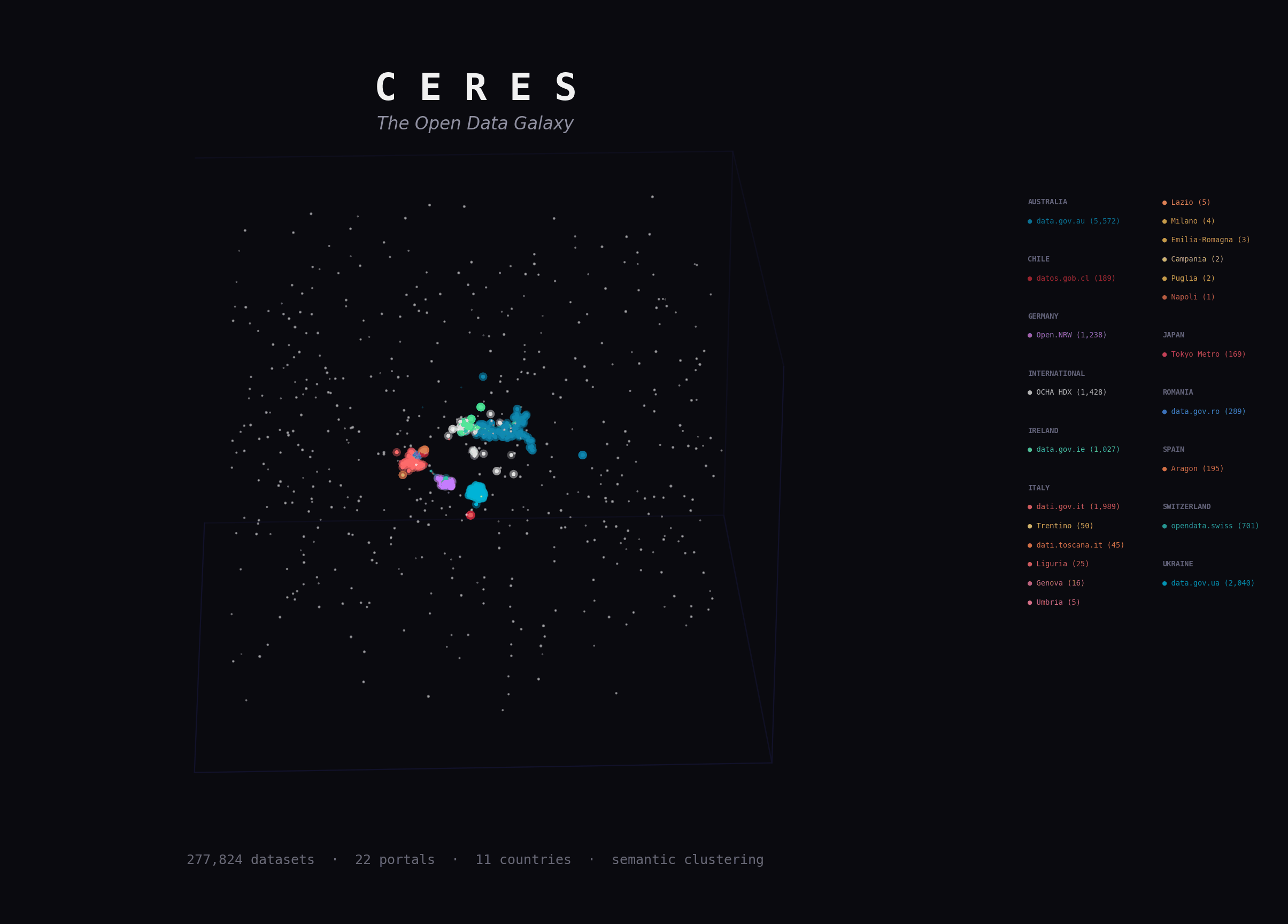
Stream metadata from CKAN, DCAT udata, and SPARQL-backed DCAT portals into PostgreSQL, track sync history, detect stale datasets, and keep the catalog current even when embeddings are disabled.
Harvesting and embedding are separate services. Run metadata-only syncs, backfill embeddings later, or switch provider without re-harvesting your sources.
When you do want vectors, Ollama gives you a local zero-cost path. Gemini and OpenAI remain supported, but the project no longer assumes cloud embeddings are required.
Use ceres harvest to populate the catalog, optionally in metadata-only mode. Incremental sync, delta detection, and stale marking reduce churn and keep memory bounded.
Run ceres embed when you want vectors. Ollama is the preferred local option; hosted providers are still available for teams that want them.
Search, API access, HuggingFace exports, and downstream analytics all build on the same harvested catalog.
Performance at scale and ecosystem consolidation: tuned HNSW vector index, dynamic ef_search, SPARQL-backed DCAT harvesting (e.g. data.europa.eu), more resilient batch embedding under provider failures, and internal refactors for maintainability.
Broader portal coverage (Socrata), multi-tenant operations, webhooks, and a Parquet export endpoint on the REST API.